CDI Solutions
Maximize Cluster Flexibility and Scalability with CDI
Modern computing environments must support more complex and diverse workloads than ever before. As technology has improved, leading organizations are introducing high-end HPC, AI, high-performance data analytics, and similar practices into their day-to-day workflows to extract even more value from data.
This convergence of workloads is a headache for CIOs and technology teams charged with supporting the researchers, engineers, product designers, or even end users that rely on these technologies to achieve their goals. Similarly, infrastructure procurement and management teams will find it increasingly difficult to maintain ROI and keep costs down when attempting to build solutions for these workloads.
Composable disaggregated infrastructure (CDI) is a new way of designing an environment that can dynamically provision bare-metal instances over PCIe via software. This means a single cluster can be reconfigured on the fly to support many vastly different workloads, enable multi-tenant environments, and more.
Deploying a CDI-based cluster gives you unparalleled flexibility and scalability, so you can meet whatever computing challenges your organizational objectives may demand in the future.

A Primer on CDI-based Clusters
Get a comprehensive understanding of clusters based on composable disaggregated infrastructure and what they can do for your organization.
Download the White PaperWith the uncertainty surrounding future datacenter design and the reluctance of some organizations to move to the cloud because of latency and security, performance, cost, or availability issues, HPC and AI clusters designed with composable infrastructure have never been so important.
Composable infrastructure refers to the practice of abstracting resources from their physical locations, converging them into a single resource pool, and managing them with software via a cloud-based interface. On-premises servers can be retasked to go from compute to storage nodes or vice versa. Network changes can be made on the fly. Costs go down and productivity goes up, all without moving your computing to the cloud.
Engineering hardware systems that can take advantage of composable infrastructure is one of Silicon Mechanics’ areas of expertise. Contact us to learn more about how your datacenter, HPC cluster, or AI system can benefit from composable infrastructure.
CDI: An Alternative to Clusters in the Cloud
Cloud computing is a revolutionary advancement in how data is generated, managed, and utilized. For many workloads, cloud or even hybrid cloud is a fantastic option to support some computing workloads. Compared to traditional data centers, it is cost-effective, more flexible, more scalable, and simpler to manage.
However, the cloud is not ideal for every situation. Here’s why:
Security and Privacy Risks
Many CSPs have robust security features on their platforms. Still, data must move into the cloud, live on third-party hardware, and come back down from the cloud. If you’re analysis involves personal identifiable information (PII) or proprietary data, or if you are a government organization, this is a major concern.
Dwindling ROI
Most CSPs use a pay-per-use model, which is fantastic for bursting HPC or AI workloads during peak utilization hours or handling intermittent tasks. When your workflows and workloads become more diverse and demanding, the ROI equation begins to flip, and now your utilization rate is so high that you’re paying more for the cloud than an on-premises solution. Meanwhile, your workflows and data management have become intertwined with the specifics of that CSP, locking you into their platform.
Performance
In the cloud, everything is virtualized. This is fine for simple processes like email servers or web hosting, but HPC, AI, and similar advanced computing methods demand more from the underlying hardware. If you rely on these types of workloads, the virtualized nature of cloud will slow you down.
How Does a CDI-based Cluster Work?
Composable disaggregated infrastructure leverages high-speed interconnects, like PCIe 4.0, to disassociate individual components into larger resource pools. These CPU, GPU, storage, and memory pools allow you to configure bare metal components into any server configuration needed, all at the software layer. As long as all resources are within the same cluster, their physical location within a node becomes irrelevant.
With this approach, organizations can properly support a diverse set of workloads on a single cluster. In multi-tenant environments, they can ensure maximum utilization of resources instead of letting GPUs or memory go underutilized in a node that is overprovisioned for the job at hand.
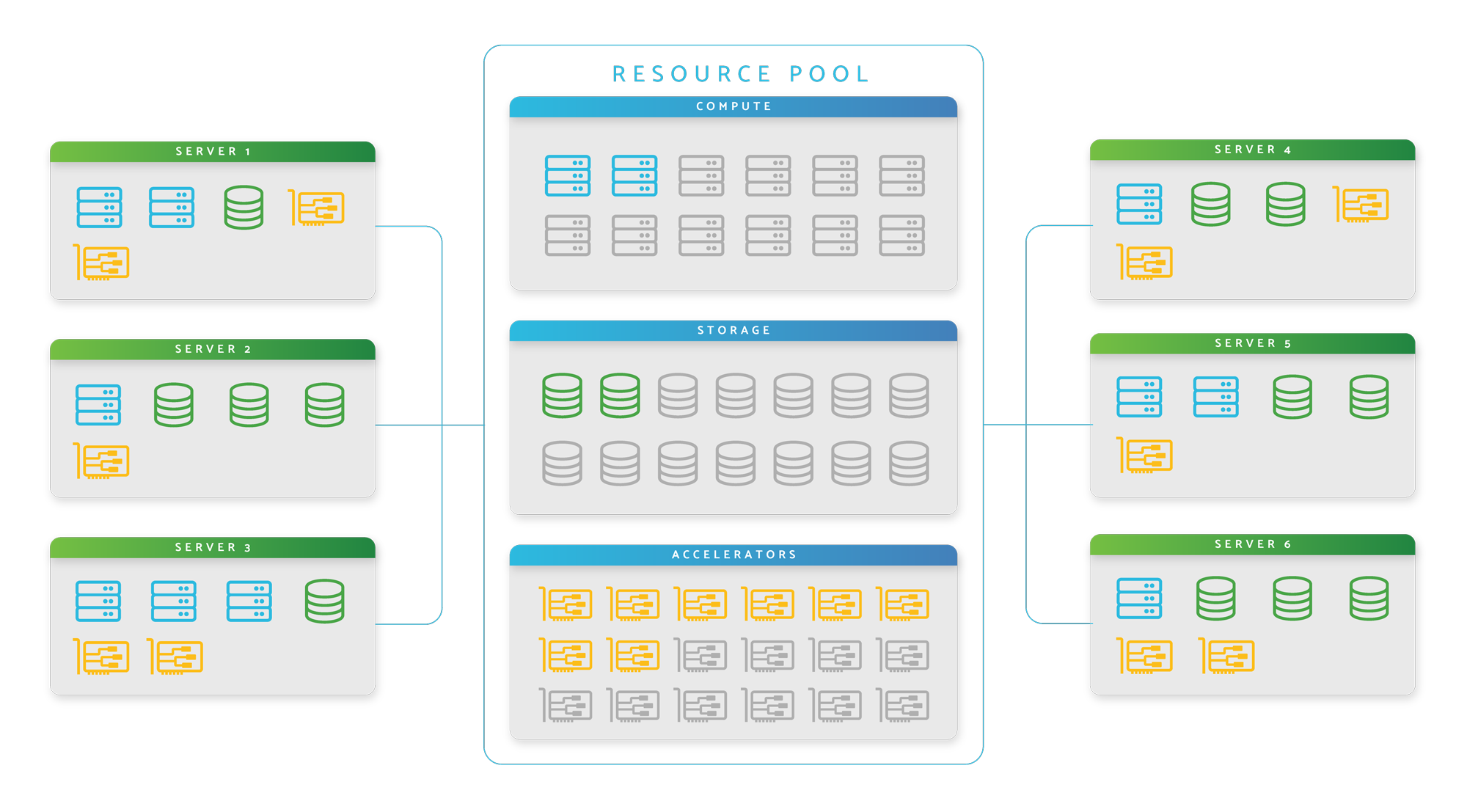
With a CDI-based approach, you could expand your small CPU-only cluster with GPU expansion chassis (think JBOD, but for PCIe devices). By doing this, you are growing the cluster you already own, instead of starting from scratch, which makes for much better ROI.
Now, not only is your computing environment more flexible and scalable, but so is your procurement and IT planning process.
A Primer on CDI-based Clusters
Get a comprehensive understanding of clusters based on composable disaggregated infrastructure and what they can do for your organization.
Download the White PaperFeatured Reference Architectures
Silicon Mechanics Miranda CDI Cluster
Expert Included
Our engineers are not only experts in traditional HPC and AI technologies, we also routinely build complex rack-scale solutions with today's newest innovations so that we can design and build the best solution for your unique needs.
Talk to an engineer and see how we can help solve your computing challenges today.