Is Composable Infrastructure the Natural Successor to Cloud Computing?

I’m sure you’ve heard the complaints: What was the point of moving to the cloud? What was the reason for going through all the trouble of investing in cloud-first infrastructure, training our staff, and adjusting all our workflows?
The shift to cloud has been a defining factor of the enterprise IT industry over the last decade. And analysts predict that the global cloud computing market will grow to over $832 billion by 2025 i. But migrating HPC to the cloud has been a slow process for a lot of organizations.
The reason so many organizations are moving to the cloud is flexibility. Cloud computing is currently unmatched in its flexibility, scalability, and ease-of-use. Anyone can create an account with a cloud service provider (CSP) and get started. You pay as you go. You can scale your usage up and down with relative ease. And each CSP has a variety of resources and tools available. It’s pretty great.
But there are downsides to the cloud, especially for HPC and AI-related workloads. For example:
But, if you want the flexibility and scalability of a public or leased private cloud environment, with less of these downsides, there is another option to consider. Composable infrastructure.
Composable infrastructure is a new way of designing an environment that can dynamically provision bare-metal instances all via software. This approach leverages PCIe interconnects to create pools of storage, compute, networking, and GPU devices to deliver dynamically configurable bare-metal servers perfectly sized with the exact physical resources required by the application being deployed. That means a system administrator can easily deploy a portion of their environment in whatever configuration the project needs, without making the performance sacrifices inherent to virtualization.
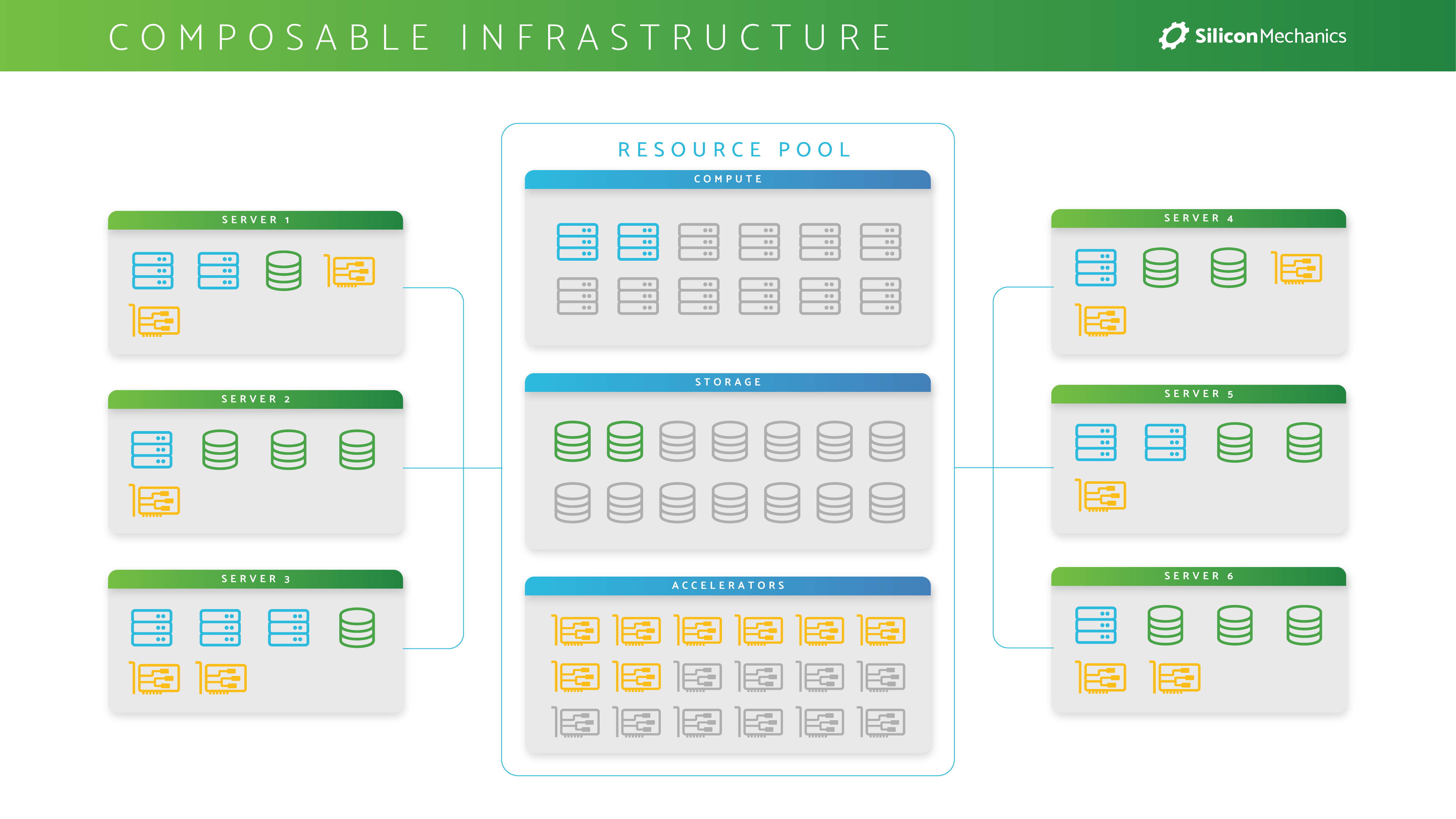
With this approach, organizations can properly support a diverse set of workloads on a single cluster. It also allows IT leaders to start small and expand their resources as needed. If you’re using virtualized server nodes in the cloud, if you end up needing GPU acceleration for a new project, you just shift to that service, but you pay whatever premium the CSP charges and may get unpredictable performance from those virtualized GPU nodes.
Instead, with a composable infrastructure approach, you could expand your small CPU-only cluster with GPU expansion chassis (Think JBOD but for PCIe Devices). By doing this you are growing your owned resources, instead of renting them from a CSP. While the initial investment to do this is higher, you avoid the recurring OpEx costs that add up over time. In a few years when those GPU resources are looking a little antiquated, they can be reassigned to support less critical workloads, instead of thrown out and replaced.
When looking at flexibility and scalability, composable infrastructure is a strong option to cloud. Where it exceeds cloud is in performance. As mentioned above, composable systems are bare-metal, which means there is no notable drop-off in performance from a normal, workload-optimized cluster built around composable infrastructure. For cutting-edge HPC and AI workloads, this performance advantage over the cloud cannot be understated.
Compared to a traditional in-house cluster, there is also a real advantage in utilization. In a traditional cluster if you have any diversity of workloads there will be stretches of time that certain resources sit unused. For instance, if a set of GPU servers are running at full capacity for only part of the day, their GPUs can be redirected to another server that needs them when they not in use. This means your utilization rate can be maximized and your total system performance can go up, which reduces the overall necessary size of your environment, saving you capital.
So if you’re looking at moving to the cloud to carry the bulk of your enterprise workloads, great, it may be the right solution for you. If you need flexibility, scalability, and low upfront costs, but can accept lower performance or higher operational expenses, you’re probably barking up the right tree.
But, if your workloads need top tier performance consider investing in a composable infrastructure system like what Silicon Mechanics is building with components from leading-edge partners like Liqid. With the flexibility and scalability of the cloud and the performance of cutting edge HPC and AI clusters, it really is the best of both worlds.
If your team could benefit from Composable Infrastructure and you’d like to learn more about the technology, we are hosting a session at GTC21. You can find more information about this and our other GTC presentations here.
i https://www.marketsandmarkets.com/Market-Reports/cloud-computing-market-234.html
About Silicon Mechanics
Silicon Mechanics, Inc. is one of the world’s largest private providers of high-performance computing (HPC), artificial intelligence (AI), and enterprise storage solutions. Since 2001, Silicon Mechanics’ clients have relied on its custom-tailored open-source systems and professional services expertise to overcome the world’s most complex computing challenges. With thousands of clients across the aerospace and defense, education/research, financial services, government, life sciences/healthcare, and oil and gas sectors, Silicon Mechanics solutions always come with “Expert Included” SM.
Latest News

Introducing DataFlow NAS
Your data is growing, your applications are evolving, and your business needs more than a basic box of disks.
READ MORE