Increasing Cluster ROI by Rightsizing

There’s been a lot of discussion lately in the analyst community about the return on investment (ROI) of high performance computing (HPC) clusters. I believe one aspect often overlooked is that most clusters are inherently incapable of achieving a high ROI for their users because of fundamental misconceptions of what an HPC cluster is or should be.
My role as a system design engineer means I speak directly to clients. I’ve found that many people – including end users – think of clusters only as hundred- or thousand-node behemoths that cost tens of millions of dollars and that are often shared by a large group of researchers. Potential users assume their cluster components must be the ones they hear about in Top 500 system designs. And they assume a lengthy lead time from when they engage with an infrastructure hardware design firm to actual researcher hands-on is inevitable.
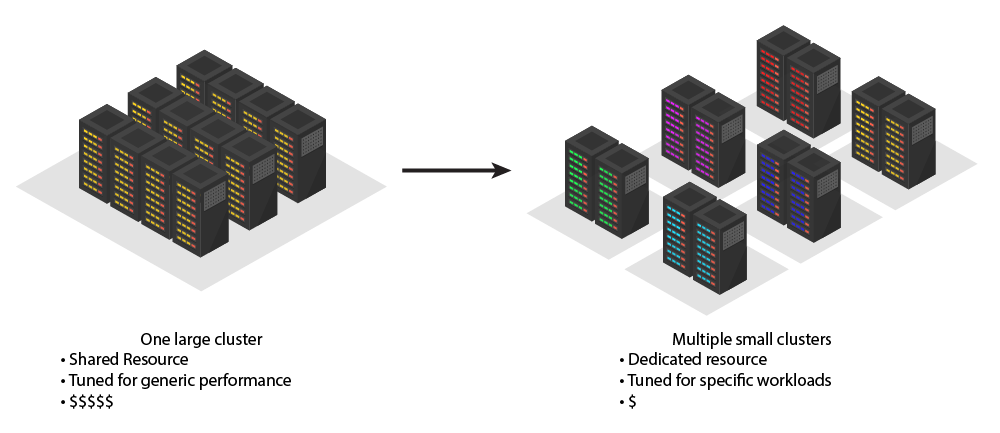
In reality, democratization of HPC from clustering really means that end users today with clusters as small as four nodes have access to as much computing power as large-scale high-performance computers of years past. Dedicated smaller clusters mean no waiting for access for a slot when other researchers are not using the larger, shared cluster.
More importantly, though, smaller HPC clusters don’t always have the same needs as big clusters, and a great number of applications don’t need bleeding-edge technology. Budgets can go much, much further with a small, well designed cluster than a more generalized design with all the latest and greatest. Often, that translates into a design solution that includes more computing power.
The more finely tuned a cluster is to the projects it is intended to run, the more effective it will be at that effort. As a result, a bespoke designed and built HPC cluster can provide bigger ROI for many use cases than the large clusters that people often ask us for, without knowing the implications. Just a few years ago, we saw a real-world example of how well a small, extremely well-tailored cluster can better meet a researcher’s needs and provide better ROI than a larger installation.
Silicon Mechanics had designed a large HPC Linux cluster for a U.S. government-sponsored national laboratory. Researchers at the lab used their cluster to conduct investigations into some of the most complex challenges facing the world today. To support those needs, their cluster had significant computing power, fast connections, and the ability to handle large data sets. It was a cluster designed to support the needs of dozens, if not hundreds of researchers simultaneously.
One researcher who used that large cluster was able to secure funding for a new, smaller cluster dedicated entirely to his research project. We discussed what his research project was about, what sort of data he was working with, how often he accessed it, how his needs differed from that of the collective group, and so on. Then we created a six-node, graphics processing unit (GPU)-accelerated cluster with current generation, but not bleeding-edge, technology for him.
Besides the GPUs, the cluster also included the AMD® EPYC™ processor, which enabled us to provide world-class performance and enough PCIe lanes to support four GPUs and high-speed HDR InfiniBand network cards. By leveraging the design of AMD EPYC processors, we were able to meet his needs with single-socket nodes, vastly reducing the cost of the cluster over dual-socket nodes. The small cluster we delivered could run his workload much more efficiently than the larger one he was trying to emulate.
To be clear, commercial off-the-shelf (COTS) systems are very well priced these days, and you can buy amazingly powerful compute servers. Anyone can take a list of technologies from a client and generate a list of modern hardware that will meet those requirements. End users will be able to run their jobs on the resulting equipment, but real ROI means finding the precise intersection of available technology and use case.
The gap between these two states is the world we live in today. This gap is the reason that we even have debates on ROI of clusters. And the gap is what’s preventing even broader adoption of clusters to more end users who could benefit from them.
I’ve met some savvy cluster system administrators. But most people who don’t design custom hardware infrastructure deployments of all sizes, day in and day out, would have a tough time optimizing the computing, networking, storage, and other aspects of a bespoke cluster to get max ROI for the end user. And it’s often hard for a sys admin to push back on a researcher’s fantasy technology list, especially when they’ve secured the budget for it.
When considering storage, for example, one of the key reasons that expectations and reality often fail to match up is the thinking behind what enterprise-grade storage really means. For example, Lustre, Ceph, and BeeGFS are all excellent storage technologies, but distributed, scale-out storage systems can be costly. More importantly, many HPC applications do not benefit from the performance of a distributed file system.
Many use cases merely require archival data storage and good – but not bleeding-edge – throughput. For these projects, where maximizing throughput won’t affect the final compute time, we have recommended smaller scale-up storage solutions with great success. In fact, sometimes just having a pool of solid state drives (SSDs) for fast scratch is all you need.
With no moving parts in SSDs, mechanical failure is less of a risk. Besides reliability, enterprise-grade NVMe SSDs can have multi-gigabyte per second throughput for barely more cost than their SATA equivalents. It may not be the sexy solution, but saving money while still getting the storage your application really needs – not what you read others are using – is a great way to improve ROI and spend your money where it can matter most.
Another major element to keep in mind for stronger ROI is networking. While most people associate HPC networking with InfiniBand, unless your application is sensitive to latency, you may have great success with smaller port count 100 Gigabit Ethernet (GbE), 50GbE, or 25GbE switches. Ethernet may be a bit old hat, but we’ve found that many users ultimately aren’t as latency sensitive as they thought. Now that they can get the throughput they need out of a more cost-effective Ethernet switch, they’re happy to put that excess money into compute.
It isn’t uncommon for us to hear system administrators who are a few years into administering an HPC system mention that their researchers’ node-to-node traffic is less than originally expected. They ask about changing their next HPC cluster networking purchase to something more aligned to the actual workloads (read “slower”), in favor of purchasing additional compute nodes. Their researchers ended up with more a few more nodes’ worth of compute performance in exchange for something they weren’t taking full advantage of anyway.
I’d love to hear fewer requests like this. End users deserve to get as much ROI as possible from their clusters. Fortunately, modern technology has evolved to the point that we can custom tailor clusters to an amazing degree today. I’m excited about a future where maximum ROI is a forgone conclusion!
About Silicon Mechanics
Silicon Mechanics, Inc. is one of the world’s largest private providers of high-performance computing (HPC), artificial intelligence (AI), and enterprise storage solutions. Since 2001, Silicon Mechanics’ clients have relied on its custom-tailored open-source systems and professional services expertise to overcome the world’s most complex computing challenges. With thousands of clients across the aerospace and defense, education/research, financial services, government, life sciences/healthcare, and oil and gas sectors, Silicon Mechanics solutions always come with “Expert Included” SM.
Latest News

Introducing DataFlow NAS
Your data is growing, your applications are evolving, and your business needs more than a basic box of disks.
READ MORE